

Options
approximate_count_distinct limitations

I would usually expect and observe approximate_count_distinct() to be much more performant than count(distinct). But here's one case where it is actually significantly slower. I am looking for an explanation why that is the case and also some kind of a general applicability scope for approximate_count_distinct(), since it looks like its benefits do not always work
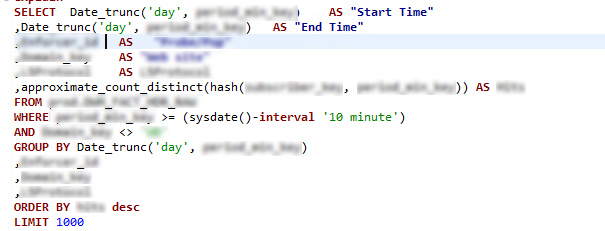
it feels like when combined with a GROUP BY each group adds a little bit of an overhead for approximate_count_distinct, eventually reaching the point of diminishing returns. Just a guess.
0
Answers
How large is the set of each group produced by GROUP BY? We Implemented approximate functions as UDX, so there is some overhead to instantiate the function and call for each group. As such, it will probably not outperform exact COUNT DISTINCT unless the sets are very large and lacking order on the counted columns, since the execution engine should be able to count ordered, encoded data very quickly compared to passing sets to UDX.
That's what I thought! Each group is about 5k rows and there are thousands of groups. I noticed that if I modify the GROUP BY statement to reduce the number of groups, the approximate_count_distinct catches up with count distinct and eventually starts to outperform it.
Thanks, Bryan!